.jpeg)
从 React 源码谈 v8 引擎对数组的内部处理
前段时间在看 Lane(以前叫做 expirationTime) 相关的代码时, 被 v8 引擎的这个注释给吸引到了. 打开研究了一番, 发现创建数组的形式不同, v8 内部的处理也不同, 因此适当的方式会对性能大有裨益, 本文做一个记录.
前言
这篇文章翻译自 Elements kinds in V8, 可配合 Mathias Bynens 的一篇演讲视频 V8 internals for JavaScript developers 一同观看.
<iframe width="100%" height="315" src="https://www.youtube.com/embed/m9cTaYI95Zc" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen> </iframe>
从 React 的源码说起
export function createLaneMap<T>(initial: T): LaneMap<T> {
// Intentionally pushing one by one.
// https://v8.dev/blog/elements-kinds#avoid-creating-holes
const laneMap = [];
for (let i = 0; i < TotalLanes; i++) {
laneMap.push(initial);
}
return laneMap;
}
先简单介绍一下 createLaneMap 这个方法, 它是用来初始化 FiberRoot 对象中的 eventTimes, expirationTimes, entanglements 属性, 其中 TotalLanes 是常量 31, 这是因为 Lane 是由 32 位二进制来表示的, 去除二进制的前导 0b, 正好是长度是 31, 如 0b0000000000000000000000000000000.
正文
JavaScript 中对象的属性可以是任意类型, 这意味着它们可以是 numeric, 可以是 Symbol, 甚至你用 undefined, null, Date 等等作为 key 都无所谓. 而对于 key 是 numeric 的情形, JavaScript 引擎是做了一些优化的, 其中最典型的就是数组索引了.
在 V8 中, 具有整数名称的属性(最常见的形式是由 Array 构造函数生成的对象, 也就是 new Array())会得到特别处理. 尽管在许多情况下这些数字索引属性的行为与其他属性一样, 但是 V8 出于优化目的选择将它们与非数字属性分开存储. 在内部, V8 甚至给这些属性一个特殊的名称: 元素. 对象具有映射到值的属性, 而数组具有映射到元素的索引.
虽然这些内部代码从未直接暴露给 JavaScript 开发人员, 但它们解释了为什么某些代码模式比其他代码模式更快.
Common element kinds
在 JavaScript 代码的运行时, V8 会对数组中的每个 element kinds 保持跟踪. 这些跟踪信息允许 V8 来对数组中的指定类型做一些优化. 举个栗子, 在你调用 reduce, map 或者 forEach 的时候, V8 可以根据数组包含的 element kinds 优化这些操作. 对于 JavaScript 来说, 它不会区分一个数字是 integers, floats, 亦或 doubles, 但在 V8 内部会有一个精确的区分.
考察下面代码: 数组一开始为 [1, 2, 3], 它的 element kinds(elements kind)在 v8 引擎内部被定义成 PACKED_SMI_ELEMENTS; 我们追加一个浮点型数字, element kinds 变成了 PACKED_DOUBLE_ELEMENTS, 而当我们再追加进一个字符串类型的元素时, element kinds 变成了 PACKED_ELEMENTS.
const arr = [1, 2, 3]; // PACKED_SMI_ELEMENTS
arr.push(4.56); // PACKED_DOUBLE_ELEMENTS
arr.push("x"); // PACKED_ELEMENTS
即便我们此时并不知道以上三种 elements kinds 的区别, 但也能隐隐感受到, v8 肯定会对纯 Int 类型元素的数组做些什么优化. 下面来具体认识一下这三种标记:
SMI 是 Small integers 的缩写
如果有双精度元素, 数组会被标记成
PACKED_DOUBLE_ELEMENTS对于有普通类型元素的, 数组会被标记成
PACKED_ELEMENTS
需要注意的是, element kinds 的转换是不可逆的, 并且方向只能从特殊到一般, 这就意味着从 PACKED_SMI_ELEMENTS 可以到 PACKED_DOUBLE_ELEMENTS, 但反之不行, 即便你后面再把 4.56 移除掉, 这个数组仍然会是 PACKED_DOUBLE_ELEMENTS.
稍作总结, 我们可以看到 v8 为数组做了这些事:
v8 会给每个数组指定 element kinds
element kinds 不是一成不变的, 随着我们对数组操作, 它会在运行时发生变化
element kinds 的转换是不可逆的, 并且方向只能从特殊到一般
PACKED vs. HOLEY kinds
上面几种标记都是针对的密集数组. 什么是密集数组呢? 比如 [1, 2, 4.56, 'x'], 它的 length 是 4, 并且这四个位置在初始化的时候都有元素.
与此相反便是稀疏数组了, 比如下面这个例子: 原本数组为 PACKED_ELEMENTS, 但我们在 arr[8] 的位置设置了一个元素, 众所周知数组内存分配空间是按照长度来的, 这就导致 arr[5] ~ arr[7] 什么都没有, 对于这种数组, 它的 elements kind 被标记成了 HOLEY_ELEMENTS.
// HOLEY_ELEMENTS
const arr = [1, 2, 4.56, "x"];
arr[8] = "hahaha";
v8 之所以做出这样的区别, 是因为操作一个 packed array 会比 holey array 得到更多的优化. 对于 packed array, 大多数操作可以高效的执行, 而操作 holey array, 需要额外付出昂贵的代价来检查原型链(这里后面会说到).
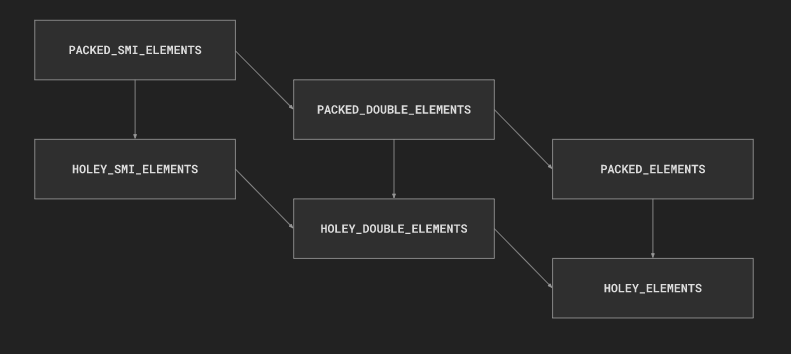
elements kind 转化关系
到此为止, 基本的 elements kind 的转化关系我们就介绍完了. 当然 v8 目前一共提供了 21 种不同的 elements kind, 都在 ElementsKind 这个枚举类型中, 每种类型都有它不同的优化方案.
通过这张图, 我们看到转化关系是不可逆的, 且只能从特殊类型到普遍类型. 更特定的元素类型支持更细粒度的优化, 元素类型在越靠右下,对该数组的操作可能就越慢. 为了获得最佳性能, 避免不必要地转换到那些普遍类型, 坚持使用最适合情况的特定类型.
Performance tips
在大多数情况下我们无需 care 这种细微的类型转换. 但是, 你可以做以下几件事来获得最大的性能.
Avoid reading beyond the length of the array
这个很好理解, 比如一个数组 arr 的长度是 5, 但你却访问了 arr[42], 因为该数组没有一个叫做 42 的属性, 因此 JavaScript 引擎必须得到原型链上查找, 直到原型链的顶端 null 为止. 一旦负载遇到这种情况, V8 就会记住"此负载需要处理特殊情况", 并且它再也不会像读取越界之前那样快.
下面这个例子, 在读取完数组中的所有元素后, 仍再读取一个越界的元素, 才跳出循环. 可能看到这段代码你会嗤之以鼻, 因为我们几乎 100% 不会这么写, 但 jQuery 里面极少代码就用到了这种模式.
for (let i = 0, item; (item = items[i]) != null; i++) {
doSomething(item);
}
取而代之, 我们用最朴素的 for 循环就够了.
const n = items.length;
for (let index = 0; index < n; index += 1) {
const item = items[index];
doSomething(item);
}
下面是原作者真实测量过的例子, 该方法传入 10000 个元素的数组, i <= array.length 要比 i < array.length 慢 6 倍(然而我测了好几遍下面的代码居然还快不少, 手动狗头).
function Maximum(array) {
let max = 0;
for (let i = 0; i <= array.length; i++) {
// BAD COMPARISON!
if (array[i] > max) max = array[i];
}
return max;
}
最后, 如果你的集合是可迭代的, 比如 NodeList, Map, Set, 使用 for...of 也是不错的选择. 而对于数组, 可以使用 forEach 等内建原型方法. 如今, 无论是 for...of 还是 forEach, 它们的性能跟传统的 for 循环已经不相上下了.
稍微扩展一下, Airbnb 的规则 no-restricted-syntax 屏蔽了 for...of, 理由如下. 不过我觉得 for...of 还是可以正常用, for...in 注意增加个 hasOwnProperty 限制就行.
iterators/generators require regenerator-runtime, which is too heavyweight for this guide to allow them. Separately, loops should be avoided in favor of array iterations.
Avoid elements kind transitions
上面就讲到了尽量不要进行 elements kind 的转换, 因为一旦转换了就是不可逆的. 这里有一些小知识, 尽管大家几乎 100% 不会做, 还是贴一下. 如 NaN, Infinity, -0 都会导致纯 Int 类型的数组变成 PACKED_DOUBLE_ELEMENTS.
const arr = [1, 2, 3, +0]; // PACKED_SMI_ELEMENTS
arr.push(NaN, Infinity, -0); // PACKED_DOUBLE_ELEMENTS
Prefer arrays over array-like objects
一些在 JavaScript 中的对象 —— 尤其在 DOM 中, 有很多的类数组对象, 有时你自己也会创建类数组对象(嗯, 只在面试中见过).
const arrayLike = {};
arrayLike[0] = "a";
arrayLike[1] = "b";
arrayLike[2] = "c";
arrayLike.length = 3;
上面的代码虽然有 index, 也有 length, 但它毕竟缺少真正数组的原型方法, 即便如此, 你也可以通过 call 或者 apply 数组的语法来使用它.
Array.prototype.forEach.call(arrayLike, (value, index) => {
console.log(`${index}: ${value}`);
});
// This logs '0: a', then '1: b', and finally '2: c'.
这段代码使用起来没啥问题, 但它仍然比真正的数组去调用 forEach 要慢, 因此如果有必要(比如要对该类数组进行大量的操作), 你可以先将该类数组对象转换为真正的数组, 再去做后续的操作, 也许这种牺牲空间换时间的方法是值得的.
const actualArray = Array.prototype.slice.call(arrayLike, 0); // 先转换为真正的数组
actualArray.forEach((value, index) => {
console.log(`${index}: ${value}`);
});
// This logs '0: a', then '1: b', and finally '2: c'.
另一个经典的的类数组是 argument, 和上面的例子一样, 同样可以通过 call 或者 apply 来使用数组的原型方法. 但随着 ES6 的普及, 我们更应该使用剩余参数, 因为剩余参数是真正的数组.
const logArgs = (...args) => {
args.forEach((value, index) => {
console.log(`${index}: ${value}`);
});
};
logArgs("a", "b", "c");
Avoid polymorphism
如果你的一个方法会处理不同元素类型的数组, 它可能会导致多态操作, 这样会比操作单一元素类型的代码要慢. 举个例子来讲, 你自己写了个数组迭代器, 这个迭代器可以传入一个纯数字类型的数组, 也可以是其他乱七八糟类型的数组, 这样就是多态操作. 当然需要注意的是, 数组内建的原型方法在引擎内部已经做了优化, 不在我们的考虑范围.
下面这个例子中, each 方法先传入了 PACKED_ELEMENTS 类型的数组, 于是 V8 使用内联缓存(inline cache, 简称 IC) 来记住这个特定的类型. 此时 V8 会"乐观的"假定 array.length 和 array[index] 在 each 内部访问函数是单调的(即只有一种类型的元素). 因此如果后续传入该方法的数组仍是 PACKED_ELEMENTS, V8 可以复用这些先前生成的代码.
但在后面分别传入了 PACKED_DOUBLE_ELEMENTS, PACKED_SMI_ELEMENTS 类型的数组, 就会导致 array.length 和 array[index] 在 each 内部访问函数被标记为多态的. V8 在每次调用 each 时需要额外的检查一次 PACKED_ELEMENTS, 并添加一个新的 PACKED_DOUBLE_ELEMENTS, 这就会造成潜在的性能问题.
const each = (array, callback) => {
for (let index = 0; index < array.length; ++index) {
const item = array[index];
callback(item);
}
};
const doSomething = (item) => console.log(item);
each(["a", "b", "c"], doSomething); // PACKED_ELEMENTS
each([1.1, 2.2, 3.3], doSomething); // PACKED_DOUBLE_ELEMENTS
each([1, 2, 3], doSomething); // PACKED_SMI_ELEMENTS
Avoid creating holes
这条就对应着开头 React 源码的考量了, 直接看代码. 方式一你创建了数组长度为 3 的空数组, 那这个数组是稀疏的, 此时这个数组会被标记成 HOLEY_SMI_ELEMENTS, 即便最后我们填满了数组, 他也不会是 packed 的, 仍然被标记成是 holey 的. 方式二是最优雅的, 它被标记成了 PACKED_ELEMENTS. 当然如果你不知道到底有多少元素, 那么就使用方式三, 即将元素 push 到一个空数组将是最好的选择.
// 方式 1 (不推荐)
const arr = new Array(3);
arr[0] = 0;
arr[1] = 1;
arr[2] = 2;
// 方式 2
const arr = ["a", "b", "c"];
// 方式 3
const arr = [];
arr.push(0);
arr.push(1);
arr.push(2);
最后
综上来讲, 这就是一篇爽文, 旨在涨涨见识. 基本百分之九十以上, 后端返回给我们的数组就已经是 PACKED_ELEMENTS 的类型了, 所以真正在乎这种内核级别优化的, 也就是如 React 这种牛逼的框架了. 当然还有一种情况, 我们似乎可以优化一番, 想想你刷动态规划的时候, 是不是初始化背包的时候就用了 new Array(n).fill(false) 这种代码呢? (手动狗头.